Spring Integration - Bulk processing Example
In this post, I'm going to share my experience in using Spring Integration for a bulk processing task. This was the first time I was using Spring Integration and it did not disappoint me. It was pretty robust in terms of error handling and definitely scalable.
Disclaimer:
The actual task being performed has been modified into a fictitious e – commerce domain task, since I cannot reveal the original task which is customer specific and confidential. However, the nature of the task in terms of processing of clob and xml remain the same and the complexity of the original task has been retained.
Also, the views posted on this post are strictly personal.
The task is to perform data processing by reading xml from a file in the file system and then store it as clob into a table.
Connect the dbInputChannel to a record splitter, which will split each of the records and put it in another channel “storageDataFileReadChannel”. So, here we are creating one thread per record read from the database and then these records are processed in parallel.
Disclaimer:
The actual task being performed has been modified into a fictitious e – commerce domain task, since I cannot reveal the original task which is customer specific and confidential. However, the nature of the task in terms of processing of clob and xml remain the same and the complexity of the original task has been retained.
Also, the views posted on this post are strictly personal.
Objective:
The objective is to work upon customer information from an ecommerce application and process it and save it into database as clob data.
The task is to perform data processing by reading xml from a file in the file system and then store it as clob into a table.
Following is the high level of tasks required to be performed:
- There will be one xml file for each customer and the file would be prefixed with the corresponding customer Id.
- The xml has customer’s personal information. The file would be named as customerID_personal.xml. For eg, 1000_personal.xml
- Read personal info file (say with name 1000_ personal.xml) from file system.
- Perform some transformation on the xml.
- Perform some more processing on the resulting xml and then save the xml into a database table as a clob data against the customerID.
Constraints:
- The volume of files is high running close to more than half a million.
- Need track of which file process succeeded and which one errored out, with reliable/robust error handling.
- This is not a real time processing application. i.e, files are dumped into the file system by a separate system and the processing can happen offline.
Design Approach:
- The customerIDs are initally saved into a table (say ALL_CUSTOMERS) with a status column (STATUS_ID), with values enumerated for NOT_STARTED, IN PROGRESS, ERROR, COMPLETE.
- Instead of polling the files in the file system, we will poll the ALL_CUSTOMERS table to get the records which are in NOT_STARTED status and process them.
- When we start processing each record, we will update it to IN PROGRESS.
- If there is any error during processing, we will update it to ERROR.
- If there is no error during processing, we will update it to COMPLETE.
Use of Spring Integration to solve this problem:
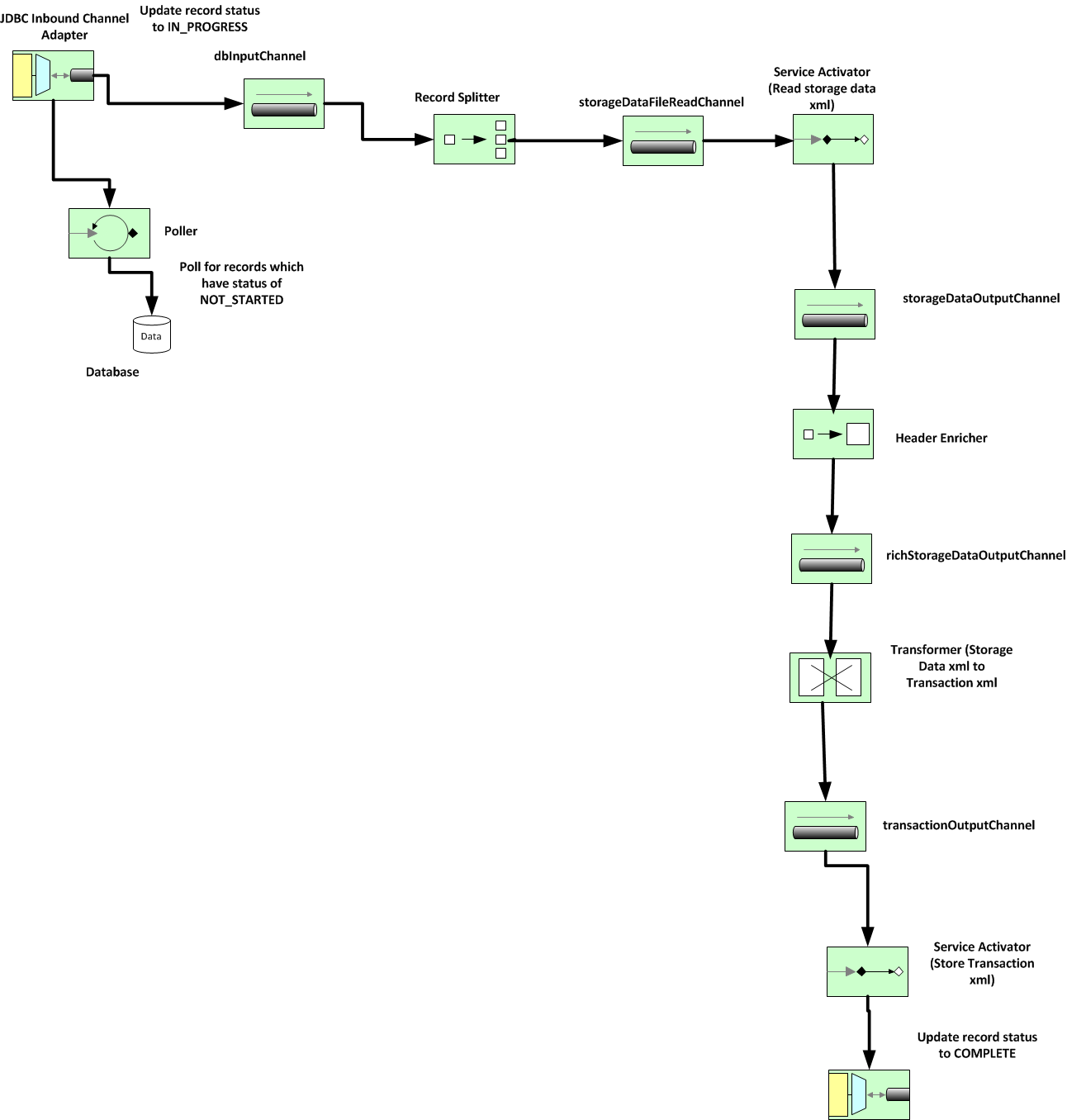
Following diagram shows the process flow.

Step 1 - Polling records from database:
Goal is to poll records which are in NOT_STARTED status and place them on a channel
- Create an inbound channel adapter which polls database at regular intervals. The inbound adapter could be a jdbc adapter. Also, we can associate a poller to the adapter to poll the database at regular intervals.
- The JDBC adapter:
- has as a query attribute, where we can specify the query to be run when the poller wakes up.
- Has a rowmapper attribute, where we can specify a POJO, which represents each record retrieved from the database.
- Has a “update” attribute, where we can specify a query which will be run after polling each record. We will use this to update the status of the polled record to “IN PROGRESS”
- The inbound channel adapter connects to a channel, “dbInputChannel” where it places the data retrieved from database.
Step 2 – Arrange for parallel processing of each of these records
Step 3 – Use of Headers
Place each of the record read as a header data (which is like session context), so that the CustomerID is available for all channels in the workflow till the end.Step 4 – Read Personal Info file from file system.
Create a service activator (which is essentially a Java service class), which reads data from a channel, invokes the service method and then places data on a output channel.- Input channel : richStorageDataFileReadChannel
- Service method: fileReadAdapter.readFile
- Output channel: richStorageDataOutputChannel
Step 5 – Perform XSLT transfomation on the personal info data
Create a Transformer which will act on the personal info data, apply XSLT transformation and place the output on an output channel.
- Input channel : transactionSourceChannel
- XSLT :xsl/customTransformation.xsl
- Output channel: transactionOutputChannel
Step 6 – Perform processing logic on the transformed data
Create a service activator (which is essentially a Java service class), which reads data from a channel, invokes the service method and then places data on an output channel. This service method will also save the data back into database and will also mark the status of the record in ALL_CUSOMERS table as COMPLETE.
- Input channel : transactionOutputChannel
- Service method: transactionService.processData
- Output channel: processedTransactionChannel
Error handling:
A global error handler is used which will set the record status to “ERROR”. This error handler would be invoked if there is any error at any step in the entire workflow.
Results, Performance:
Overall, the workflow worked like a charm. There were some errors encountered occasionally, sometimes due to invalid xml in the file system mainly due to presence of special characters.
However, the error handling mechanism took care of it, the record was marked as error and importantly, the process didn’t stop there.
The speed was good too, with a processing rate of 120 records in 5 minutes (on a not so high end processor and the original task involved two different file reads per record). Note that I had set the timer to poll the database every 5 minutes. It could process 120 records in parallel, before it could start the next poll.
Conclusion:
I would recommend to use Spring Integration because of its ease of use and robustness. It is well documented too and is a good fit for bulk processing.
the explanation of this topic you posted is very good. please upgrade the new technologies about this topic.
ReplyDeleteSelenium Training in Bangalore
Best Selenium Training Institute in Bangalore
Data Analytics Courses in Bangalore
Digital Marketing Courses in Bangalore
Python Training in Bangalore
Big Data Training in Bangalore
Hacking Course in Bangalore
Selenium Course in Bangalore
I am feeling happy to read this. You gave nice info to me. Please update more.
ReplyDeleteEthical Hacking course in Chennai
Ethical Hacking Training in Chennai
Hacking course in Chennai
ccna course in Chennai
Salesforce Training in Chennai
AngularJS Training in Chennai
PHP Training in Chennai
Ethical Hacking course in Tambaram
Ethical Hacking course in Velachery
Ethical Hacking course in T Nagar
This comment has been removed by the author.
ReplyDeleteInnovative blog...!!! This is the best post and I got more ideas from your post. Keep continuous....
ReplyDeleteJMeter Training in Chennai
Excel Training in Chennai
Embedded System Course Chennai
Linux Training in Chennai
Pega Training in Chennai
Tableau Training in Chennai
Power BI Training in Chennai
Spark Training in Chennai
Oracle Training in Chennai
Job Openings in Chennai
This comment has been removed by the author.
ReplyDeleteI'm really impressed with your effort...Thanks for sharing this information with us.
ReplyDeleteIt's really nice and meaningful. It's really cool blog.
Digital Marketing Training in Chennai | Certification | SEO Training Course | Digital Marketing Training in Bangalore | Certification | SEO Training Course | Digital Marketing Training in Hyderabad | Certification | SEO Training Course | Digital Marketing Training in Coimbatore | Certification | SEO Training Course | Digital Marketing Online Training | Certification | SEO Online Training Course
Hi buddies, it is great written piece entirely defined, continue the good work constantly.
ReplyDeleteData Science Course
Wonderful Post. With one of a kind substance, I truly motivate enthusiasm to peruse this post. I trust this article help huge numbers of them who looking this pretty data.
ReplyDeleteCyber Security Training Course in Chennai | Certification | Cyber Security Online Training Course | Ethical Hacking Training Course in Chennai | Certification | Ethical Hacking Online Training Course | CCNA Training Course in Chennai | Certification | CCNA Online Training Course | RPA Robotic Process Automation Training Course in Chennai | Certification | RPA Training Course Chennai | SEO Training in Chennai | Certification | SEO Online Training Course
Impressive blog to be honest definitely this post will inspire many more upcoming aspirants. Eventually, this makes the participants to experience and innovate themselves through knowledge wise by visiting this kind of a blog. Once again excellent job keep inspiring with your cool stuff.
ReplyDeleteDigital Marketing Course
Blog has informative contents and thanks for sharing this.
ReplyDeletePython Classes in Chennai
Best Python Training in Bangalore